Zadanie
Klient miał proste wymaganie: zaimportować dane Salesforce do dbt. Zapytaliśmy, ile obiektów. Przesłali listę 20+.
Od razu wiedzieliśmy, że nie chcemy spędzić całego dnia na pisaniu powtarzalnych modeli SQL, kopiowaniu nazw pól i utrzymywaniu plików YAML dla każdego z nich. Za każdym razem, gdy Salesforce zmieniał pole, musielibyśmy wszystko poprawiać ręcznie. Nie wchodziło w grę.
Podejście
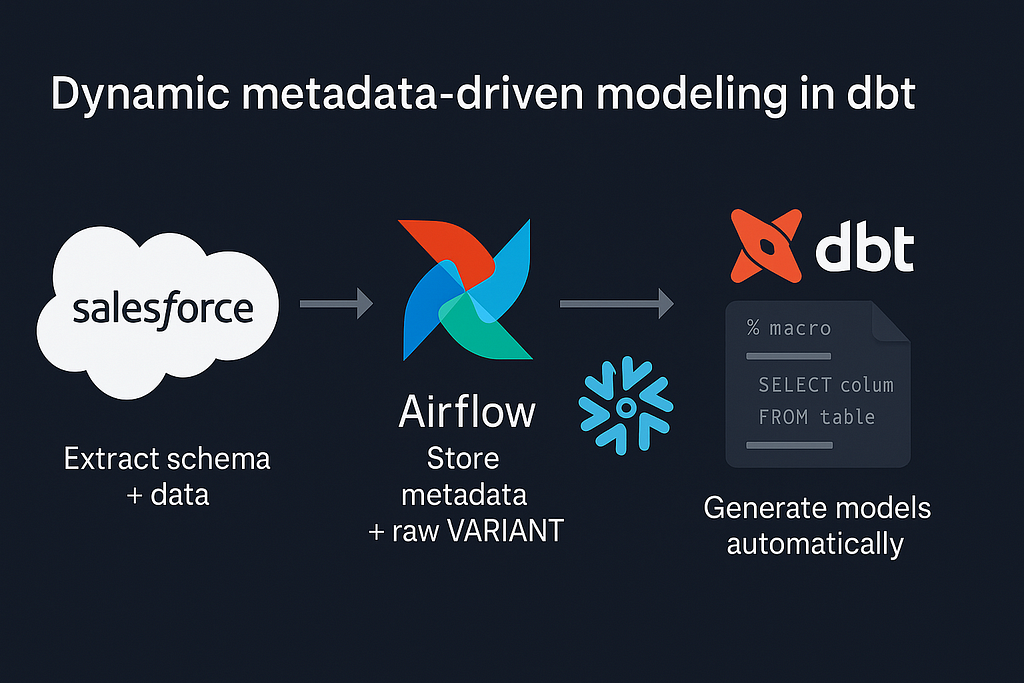
Używamy Airflow jako orchestratora, więc zaczęliśmy od DAG-a odpowiedzialnego za ekstrakcję schematu i synchronizację danych. Celem było dynamiczne pobieranie metadanych Salesforce i zapis do Snowflake dla dbt.
Krok 1 — Pobieranie schematu Salesforce
Salesforce udostępnia endpoint API opisujący metadane obiektu:
GET /services/data/v59.0/sobjects/{OBJECT_NAME}/describe/Dokumentacja: https://developer.salesforce.com/docs/atlas.en-us.api_rest.meta/api_rest/resources_sobject_describe.htm
Fragment odpowiedzi:
{
"fields": [
{"name": "Id", "type": "id"},
{"name": "Name", "type": "string"},
{"name": "OwnerId", "type": "reference"},
{"name": "CreatedDate", "type": "datetime"}
]
}W Airflow opakowaliśmy to w prosty task w Pythonie: każde uruchomienie DAG-a iteruje po liście obiektów i odświeża metadane dla każdego z predefiniowanej listy. Wszystko trafia do tabeli sf_metadata_fields w bazie Snowflake.
Krok 2 — Przechowywanie surowych obiektów
Każdy obiekt Salesforce był też zapisywany osobno w Snowflake. Nie chcieliśmy scalać wszystkiego w jeden zestaw danych, bo każdy obiekt miał zupełnie inną strukturę i łatwiej było je znaleźć w Snowflake w ten sposób.
Podczas ingestii spłaszczaliśmy surową odpowiedź API i zapisywaliśmy w tabelach per obiekt w schemacie raw_data. Każdy rekord miał jedną kolumnę record VARIANT z całym payloadem JSON z Salesforce:
create or replace table raw_data.account as
select
metadata$filename as file_name,
metadata$file_row_number as row_number,
to_variant($1) as record,
current_timestamp() as _load_time
from @salesforce_stage/account/*.json.gz;
To pozwoliło utrzymać ingestę generyczną — jeden operator ingestii, wiele obiektów — bez definiowania mapowania kolumn z góry. dbt później czytał metadane z sf_meta_fields i dynamicznie rzutował pola record w generowanych modelach stagingowych.
Krok 3 — Dynamiczne generowanie modeli dbt
Gdy metadane schematu są w Snowflake, przejmują makra dbt. Napisaliśmy makro generujące modele stagingowe dynamicznie. Zaczynamy od pobrania metadanych z tabeli Snowflake przez run_query() w makrze pomocniczym:
{% macro sf_get_object_fields_with_types(object_name) %} -- salesforce object name
{% set query %}
select field_name, field_type
from {{ source('salesforce', 'sf_meta_fields') }}
where object_name = '{{ object_name }}'
{% endset %}
{% set results = run_query(query) %} -- run_query
{% if execute %} -- ensure macro only runs in "execute" mode (not during dbt compile dry-run)
{% set fields = [] %} -- iterate through each row returned by run_query()
{% for row in results.rows %}
-- append each (field_name, field_type) pair to the fields list
{% do fields.append({
"field_name": row[0],
"field_type": row[1]
}) %}
{% endfor %}
-- return the full list of dictionaries to the parent macro
{% do return(fields) %}
{% endif %}
{% endmacro %}To makro działa w czasie kompilacji — run_query() wykonuje SQL w Snowflake podczas kompilacji dbt, zwracając listę kolumn i ich typów z naszej tabeli metadanych.
Wynik jest konsumowany przez makro generatora, które produkuje w pełni typowany model automatycznie:
{% macro generate_stg_model(object_name) %}
{% set fields = sf_get_object_fields_with_types(object_name) %}
select
{% for f in fields %}
record:"{{ f.field_name }}"::{{ f.field_type }} as {{ f.field_name }}{% if not loop.last %},{% endif %}
{% endfor %}
from {{ source('salesforce', object_name) }}
{% endmacro %}To wszystko — dbt wykonuje run_query() w makrze w czasie kompilacji, pobierając metadane bezpośrednio ze Snowflake i generując pełny model SQL dynamicznie.
Przykładowe polecenie:
{{ generate_stg_model("Account") }}które generuje:
select
record:"Id"::varchar as Id,
record:"Name"::varchar as Name,
record:"OwnerId"::varchar as OwnerId,
record:"CreatedDate"::timestamp_ntz as CreatedDate,
...
from {{ source('salesforce', 'Account') }}
Krok 4 — Automatyczne generowanie YAML
Później zautomatyzowaliśmy dokumentację schematu przez dbt-codegen:
dbt run-operation generate_model_yaml --args '{"model_name": "stg_salesforce_account"}'i scaliliśmy opisy pól z sf_meta_fields, wzbogacając YAML o metadane pól Salesforce.
Pamiętaj, że musisz dodać dbt-codegen do packages.yml i uruchomić dbt deps przed tym poleceniem — inaczej dbt nie rozpozna makra.
Rezultat
- 20+ modeli zbudowanych i udokumentowanych automatycznie
- Schema drift obsługiwany automatycznie przy następnym uruchomieniu Airflow
- Bez ręcznego typowania, błędów copy-paste i narzutu utrzymaniowego
Wniosek
Jeśli modelujesz dane z zewnętrznych CRM-ów jak Salesforce, HubSpot czy Dynamics — zawsze sprawdź endpointy „describe” lub metadanych. Nie są popularne, ale mogą zamienić cały dzień ręcznej pracy w w pełni zautomatyzowany workflow, który sam się aktualizuje i dokumentuje.
Joachim Hodana - Software & Data Engineer
Automating Salesforce → dbt Models: Dynamic Metadata-Driven Modeling został pierwotnie opublikowany w Lortech Solutions Blog na Medium, gdzie rozmowa trwa dalej dzięki podświetleniom i odpowiedziom czytelników.