Zbierz każdy skrypt cron, starszy plik EXE, zadanie PowerShell i job w Pythonie w jednym dashboardzie hostowanym przez Ciebie — bez wysyłania ani jednego bajta do dostawcy SaaS.
Część 3 z 3 w serii o obserwowaniu systemu .NET za pomocą OpenTelemetry i SigNoz (indeks serii). Wykorzystuje Collector, plik Compose i instalację SigNoz z Części 1.
Aplikacje webowe to łatwa część observability. Trudna to wszystko inne, co utrzymuje firmę po godzinach: nocny cron odziedziczony po poprzedniku, ETL w Pythonie prowadzony przez zespół danych, zadanie backupu w PowerShell, 12-letni eksporter, który zapisuje wyłącznie export-20260529.txt. Nie da się tego rozwiązać przez dotnet add package — to właśnie te zadania często cicho padają o 3 w nocy.
Ten artykuł pokazuje, jak wprowadzić je wszystkie do SigNoz, działającego w całości na Twojej infrastrukturze. Na końcu będziesz w stanie obserwować zadanie niezależnie od tego, gdzie leży na spektrum — od „tylko zapisuje pliki tekstowe” po „pełny OpenTelemetry SDK”. Na końcu znajdziesz wszystkie skrypty i konfiguracje — nie ma repozytorium do sklonowania.
Czego się nauczysz
- Dlaczego observability on-prem pasuje do zadań w tle
- Jak OpenTelemetry Collector działa jako uniwersalne wejście dla czegokolwiek
- Przypadek A: zbieranie zadania, które zapisuje wyłącznie pliki
.txt(bez zmian w kodzie) - Przypadek B: instrumentacja zadania w Pythonie za pomocą OpenTelemetry SDK
- Przypadek C: telemetry z PowerShell, który nie ma oficjalnego SDK
- Jak wszystkie pojawiają się obok siebie w SigNoz
Dlaczego on-prem?
SigNoz jest w pełni open-source i self-hosted — dla zadań w tle to ma większe znaczenie niż prawie dla czegokolwiek innego:
- Twoje dane zostają w Twojej sieci. Zadania wsadowe dotykają najbardziej wrażliwych danych — eksporty finansowe, PII, kopie zapasowe. Przy self-hosted SigNoz telemetria o tej pracy nigdy nie opuszcza infrastruktury. To realna przewaga w środowiskach regulowanych lub odizolowanych, gdzie wysyłanie logów do SaaS w ogóle nie wchodzi w grę.
- Brak niespodziewanego rachunku za GB. Zadania są głośne — rozbudowane logi, częste uruchomienia. W SaaS rozliczanym za użycie to logi z jobów rozdmuchują rachunek. Self-hosted koszt to maszyna, na której to działa.
- Działa tam, gdzie działają zadania. Wiele z nich działa na serwerze on-prem lub zamkniętej VM bez wychodzącego internetu. Collector i SigNoz stoją tuż obok.
Wszystko w tym artykule działa lokalnie: aplikacje i Collector w Twojej sieci, a SigNoz przechowuje dane we własnej bazie ClickHouse na Twojej infrastrukturze. Nic nie wychodzi na zewnątrz.
Jedna idea: Collector jako wejście
Oto cały model mentalny. OpenTelemetry Collector to mała usługa, która przyjmuje telemetrię z wielu źródeł i przekazuje ją do SigNoz. Aplikacje, którymi zarządzasz, mówią do niego bezpośrednio OTLP. Aplikacje, którymi nie zarządzasz, są adaptowane w Collectorze:
in-solution .NET worker ──OTLP──┐
Python job (OTEL SDK) ──OTLP────┤
PowerShell (OTLP/HTTP) ─────────┤──▶ OpenTelemetry Collector ──▶ SigNoz (on your infra)
legacy job (.txt files) ─(filelog reads the files)─┘
Pomyśl o zadaniach na drabinie dojrzałości — Collector obsługuje każdy szczebel:
- Brak telemetrii, tylko pliki logów → Collector czyta pliki (receiver
filelog) i zamienia każdą linię w rekord logu. - Może pisać ustrukturyzowane linie lub POSTować payload, ale bez SDK → pliki JSON-lines lub OTLP/HTTP po sieci.
- Ma prawdziwe SDK (Python, Java, Go, Node) → ślady, metryki i logi natywnie.
Pozycja zadania na drabinie zmienia tylko jak sygnał trafia do środka — nigdy gdzie ląduje. Zacznijmy od dołu drabiny, bo to najtrudniejszy i najczęstszy przypadek.
Łatwy przypadek (dla kontrastu): worker .NET w rozwiązaniu
Jeśli masz kod i to .NET, wystarczy jedna linia. Worker w tle wywołuje ten sam helper AddObservability używany przez aplikacje webowe (pełne źródło w Części 1), wskazuje na własną klasę WorkerTelemetry niestandardowych instrumentów (pełne źródło w załączniku) i wyłącza instrumentację serwera web:
builder.AddObservability("worker-jobs", options =>
{
options.InstrumentAspNetCore = false; // not a web server
options.ActivitySources.Add(WorkerTelemetry.ActivitySourceName);
options.Meters.Add(WorkerTelemetry.MeterName);
});
To złoty standard: własne spany, własne metryki — a ponieważ jego HttpClient jest zinstrumentowany — automatyczne rozproszone ślady (worker-jobs → backend-api → db). Wszystko poniżej to to, co robisz, gdy nie możesz wykonać tego jednego wywołania.
Przypadek A — zadanie, które zapisuje wyłącznie pliki .txt
To zadanie spotkasz najczęściej: starszy eksporter, bez SDK, bez kodu źródłowego do zmiany. Tylko dopisuje czytelne dla człowieka linie:
2026-05-29 12:00:00 [INFO] run #3: wrote 161 records to dataset
2026-05-29 12:00:21 [ERROR] run #7: export failed: connection reset by peer
at LegacyExporter.Flush(batchId=7)
at LegacyExporter.Run()
Zbierasz je za pomocą receivera filelog Collectora, który śledzi pliki i zamienia każdy wpis w rekord logu. Oto konfiguracja z wyjaśnieniem każdej części:
receivers:
filelog/legacy:
include: [/var/log/legacy/*.txt] # 1. which files (glob handles daily rotation)
start_at: beginning
multiline: # 2. keep stack traces together
line_start_pattern: '^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}'
operators:
- type: regex_parser # 3. split each entry into fields
regex: '(?s)^(?P<ts>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) \[(?P<sev>\w+)\] (?P<msg>.*)$'
timestamp: { parse_from: attributes.ts, layout: '%Y-%m-%d %H:%M:%S' }
severity: { parse_from: attributes.sev }
- type: move # 4. put the message in the log body
from: attributes.msg
to: body
Co robi każda ponumerowana część:
includeto glob, więcexport-20260529.txt,…30.txt, … są wszystkie łapane — bez zmiany konfiguracji przy zmianie daty.multiline.line_start_patternmówi: „nowy wpis logu zaczyna się tylko na linii ze znacznikiem czasu”. Bez tego czteroliniowy stack trace to cztery bezużyteczne rekordy. Z tym linia[ERROR]i jej ramkiat …stają się jednym rekordem. To najważniejsze ustawienie dla starszych logów.regex_parserwyciąga znacznik czasu, severity i wiadomość. Wiodące(?s)ma znaczenie: silnik regex Go potrzebuje go, aby.obejmowało znaki nowej linii — bez tego wieloliniowe błędy nie parsują się. Bloktimestampsprawia, że SigNoz używa własnego czasu logu, aseveritymapujeINFO/WARN/ERROR— dzięki temu działa filtrowanie po severity.moveprzenosi czystą wiadomość do body logu.
Jeszcze jeden krok: plik nie ma nazwy usługi, więc nadajemy ją procesorem resource i kierujemy przez własny pipeline logów:
processors:
resource/legacy:
attributes:
- { key: service.name, value: legacy-batch-job, action: upsert }
- { key: service.namespace, value: blazor-signoz, action: upsert }
service:
pipelines:
logs/filelog:
receivers: [filelog/legacy]
processors: [resource/legacy, batch]
exporters: [otlp/signoz]
(Ten receiver, processor i pipeline są częścią pełnej konfiguracji Collectora w załączniku Części 1.)
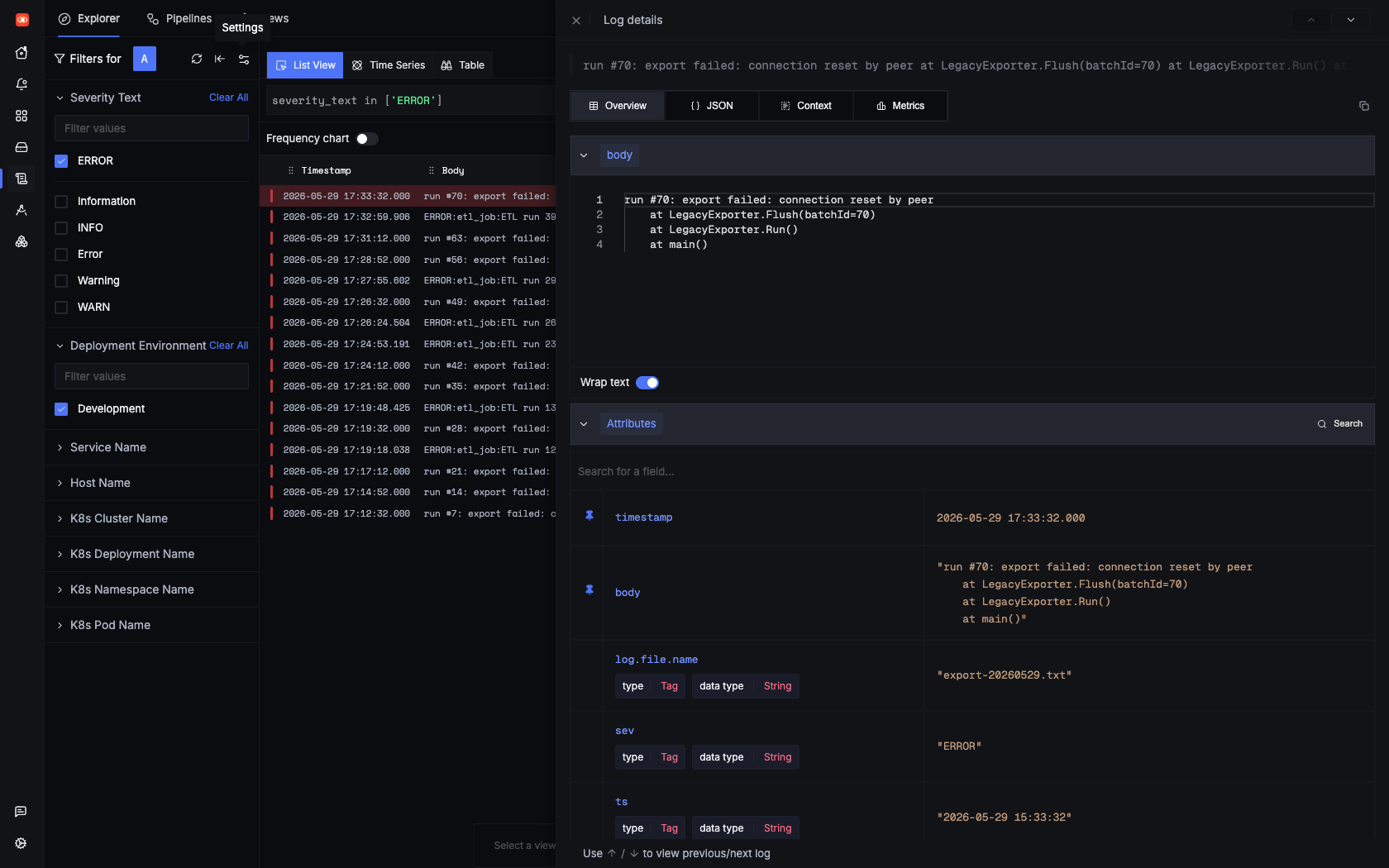
Teraz zadanie oparte wyłącznie na plikach grupuje się pod legacy-batch-job w SigNoz, tuż obok prawdziwych usług. Oto efekt — wieloliniowy błąd jako jeden sparsowany rekord:
Zadanie, które zapisuje wyłącznie pliki .txt, w SigNoz. Linia [ERROR] i jej trzy ramki stack trace at … to jedno body rekordu; severity parsuje się do ERROR, znacznik czasu pochodzi z logu, a log.file.name wskazuje plik źródłowy — wszystko w Collectorze, bez zmian w zadaniu.
Uwaga on-prem — nie trać pozycji odczytu. Demo używa
start_at: beginningcelowo, aby przy pierwszym starcie Collectora zobaczyć istniejące linie.txt. Samo w sobie przy każdym restarcie czyta od początku (duplikaty), podczas gdystart_at: endpomija to, co zapisano, gdy Collector był wyłączony (luki). W produkcji dodaj rozszerzeniefile_storage, aby offsety odczytu przetrwały restarty:extensions: file_storage: { directory: /var/lib/otelcol/storage } receivers: filelog/legacy: { include: [/var/log/legacy/*.txt], start_at: end, storage: file_storage }
Przypadek B — Python z OpenTelemetry SDK
Gdy język zadania ma prawdziwe SDK — użyj go. Job ETL w Pythonie produkuje ślady, metryki i logi o takim samym kształcie jak usługi C#, z zaledwie trzech pakietów:
opentelemetry-api
opentelemetry-sdk
opentelemetry-exporter-otlp-proto-grpc
Budujesz jeden Resource (tożsamość zadania) i współdzielisz go między trzema providerami, więc wszystko grupuje się pod jedną usługą:
resource = Resource.create({"service.name": "python-etl-job", "service.namespace": "blazor-signoz"})
tracer_provider = TracerProvider(resource=resource)
tracer_provider.add_span_processor(BatchSpanProcessor(OTLPSpanExporter(endpoint=ENDPOINT, insecure=True)))
trace.set_tracer_provider(tracer_provider)
tracer = trace.get_tracer("etl_job")
Konfigurujesz meter_provider (dla metryk python.etl.*) i logger_provider (dla logów) w identycznym kształcie — pełny skrypt jest w załączniku.
Potem praca naturalnie zagnieżdża spany, więc SigNoz pokazuje wodospad extract → transform → load:
with tracer.start_as_current_span("python.etl.run"):
with tracer.start_as_current_span("extract"): ...
with tracer.start_as_current_span("transform"): ...
with tracer.start_as_current_span("load"): ...
Jedno uruchomienie ETL jako ślad. Główny span python.etl.run (484 ms) zawiera extract, transform i load, dokładnie tak jak bloki with je zagnieżdżają. To uruchomienie to jedno z ok. 15%, które kończą się błędem na load — span jest czerwony, a nagłówek pokazuje Errors: 1, więc widzisz etap i moment awarii bez otwierania pliku logu na maszynie. Skrypt Python czytany od góry do dołu, pokazany tak samo jak rozproszony ślad mikrousługi.
Jednej linii krótkotrwałe zadania nie mogą pominąć: procesory batch buforują telemetrię i opróżniają ją na timerze. Zadanie kończące się normalnie traci to, co jeszcze jest w buforze — ostatnie spany i logi znikają. Zawsze opróżniaj przed wyjściem:
finally: tracer_provider.shutdown(); meter_provider.shutdown(); logger_provider.shutdown()To główna przyczyna „mój cron się wykonał, a nic nie widzę”.
Nie chcesz ruszać skryptu? Użyj auto-instrumentacji zero-code:
pip install opentelemetry-distro opentelemetry-exporter-otlp
opentelemetry-bootstrap -a install
OTEL_SERVICE_NAME=python-etl-job \
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:5317 OTEL_EXPORTER_OTLP_PROTOCOL=grpc \
opentelemetry-instrument python etl_job.py
(Ustaw OTEL_EXPORTER_OTLP_PROTOCOL=grpc, bo 5317 to port gRPC Collectora; dystrybucja auto-instrumentacji domyślnie używa OTLP/HTTP, co wymagałoby portu 5318.)
Daje to ślady i logi za darmo; przejdź na ręczne SDK dopiero, gdy chcesz własne spany jak extract/transform/load i własne metryki.
Przypadek C — PowerShell bez oficjalnego SDK
PowerShell nie ma oficjalnego OpenTelemetry SDK, więc mały helper do dot-source (OtelExport.ps1, w załączniku) oferuje dwie pragmatyczne ścieżki.
Opcja A — zapis JSON-lines do pliku (najbardziej niezawodna). Skrypt dopisuje jeden obiekt JSON na linię; receiver filelog Collectora łapie to przez json_parser:
Write-JobLog -Message "Backed up $files files" -Level INFO -Attributes @{ files = $files }
# -> {"time":"2026-05-29T12:00:00...","level":"INFO","msg":"Backed up 231 files","files":231}
Po stronie Collectora to drugi receiver filelog, jak legacy w Przypadku A, ale z json_parser zamiast regex — dodaj obok filelog/legacy i podłącz do pipeline logów:
receivers:
filelog/powershell:
include: [/var/log/powershell/*.log]
start_at: beginning
operators:
- type: json_parser
timestamp: { parse_from: attributes.time, layout: '%Y-%m-%dT%H:%M:%S.%L%z' }
severity: { parse_from: attributes.level }
- type: move # promote the message to the log body
from: attributes.msg
to: body
To najbezpieczniejsza opcja: skrypt nie blokuje się na sieci, a gdy Collector padnie, nadrobi później. Najlepsza dla zadań wsadowych.
Opcja B — bezpośredni POST OTLP/HTTP (czas rzeczywisty). Send-OtelLog / Send-OtelTrace POSTują JSON prosto na port HTTP Collectora (:4318) przez Invoke-RestMethod. Dostajesz prawdziwe spany w trakcie pracy — ale OTLP/JSON ma ostre krawędzie, a helper obsługuje każdą z nich:
- 64-bitowe znaczniki czasu muszą być cytowanymi stringami.
timeUnixNanobuduje się jako string (([long]$ms * 1000000).ToString()), bo liczby JSON nie pomieszczą bezpiecznie int64. - ID śladu/spana to hex, nie base64 — 32 znaki hex dla śladu, 16 dla spana.
- Enumy to liczby całkowite —
severityNumber(INFO = 9),kindspana,codestatusu. ConvertTo-Json -Depth 12— domyślna głębokość 2 po cichu obcina zagnieżdżoną strukturęresourceLogs → scopeLogs → logRecords.
Co wybrać? Plik (Opcja A) dla zadań wsadowych, gdy trwałość ważniejsza od opóźnienia; OTLP/HTTP (Opcja B), gdy chcesz spany w czasie rzeczywistym. Oba naraz prawie nic nie kosztują — przykładowy job robi dokładnie to.
Logi zadania backupu w SigNoz, filtrowane do service.name = powershell-backup-job. Każda linia „Backed up N files” to ustrukturyzowany rekord POSTowany z PowerShell przez OTLP/HTTP, z severity (INFO) i atrybutem files zachowanym — nie płaska linia tekstu. Usługa pojawia się w lewym filtrze tuż obok backend-api, blazor-frontend i python-etl-job, mimo że PowerShell nie ma SDK.
To nie tylko logi. Ręcznie złożony OTLP/JSON z Opcji B produkuje prawdziwy span, więc ten sam skrypt widać w Traces:
Prawdziwy span distributed tracing emitowany skryptem PowerShell. Span backup (463 ms) to całe zadanie na usłudze powershell-backup-job, zbudowany ręcznie w Send-OtelTrace i POSTowany jako OTLP/JSON — hex ID, cytowane nanosekundowe znaczniki czasu i reszta. Tu to jeden span, bo zadanie wykonuje jedną jednostkę pracy, ale nic nie stoi na przeszkodzie, by zagnieżdżać spany potomne jak w ETL Python. Chodzi o to, że nawet język bez SDK ląduje w tym samym widoku Traces co usługi C#.
Zobacz wszystko w SigNoz
Postaw stos, wygeneruj ruch i uruchom zadania (polecenia poniżej). Efekt: worker C#, skrypt Python i skrypt PowerShell trafiają na tę samą listę Services (współdzielą service.namespace), a zadanie legacy oparte wyłącznie na .txt pojawia się w Logs:
python-etl-job i powershell-backup-job są na liście Services tuż obok backend-api, blazor-frontend i worker-jobs. (Zadanie legacy oparte wyłącznie na .txt pojawia się w Logs, nie na liście APM, bo nie emituje spanów.)
Następnie:
- Logs — filtruj
service.name = legacy-batch-job, potem severityERRORi otwórz jeden: komunikatconnection reset by peeri jego trzy ramkiat …to jeden zgrupowany rekord. - Traces — filtruj
service.name = python-etl-job, otwórz śladpython.etl.runi zobacz wodospadextract → transform → load(ok. 15% uruchomień kończy się błędem naload, celowo). - Metrics — wykres
python.etl.rows_processedipython.etl.runsz podziałem nasuccess.
Ile to kosztuje w utrzymaniu
On-prem odwraca model kosztów: brak rachunku za GB ingestu, tylko dysk, który już masz. W zamian Ty decydujesz, jak długo żyją dane, a gadatliwy pipeline filelog może zapełnić dysk, jeśli na to pozwolisz.
Retencję w SigNoz ustawiasz per sygnał w Settings → General (pod spodem to TTL ClickHouse). Dostosuj każdy sygnał do jego wartości i wolumenu:
- Logs to sygnał o największym wolumenie — trzymaj krótko (np. 15 dni). Sam pipeline legacy
.txtmoże być hałaśliwy. - Traces są skokowe; tydzień lub dwa zwykle wystarcza do analizy incydentów.
- Metrics po agregacji są małe — trzymaj najdłużej (kwartał lub więcej) dla trendów pojemności i porównań rok do roku.
ClickHouse mocno kompresuje telemetrię (często ok. 10×), więc sizing jest znacznie tańszy niż sugeruje surowy wolumen, ale dyscyplina jest taka jak w każdym self-hosted store: ustaw retencję świadomie, obserwuj dysk i próbkuj głośne źródła (patrz uwaga o sampling w Części 2), zanim staną się problemem.
Ściągawka — która ścieżka dla którego zadania
| Zadanie… | Użyj | Dostajesz |
|---|---|---|
Zapisuje wyłącznie pliki .txt/log, nie da się zmienić | Receiver filelog Collectora | Logi (z severity + multiline) |
| Pisze ustrukturyzowane linie, bez SDK | Plik JSON-lines + json_parser | Logi ze sparsowanymi polami |
| Może HTTP POST, bez SDK | OTLP/HTTP przez Invoke-RestMethod | Logi + spany w czasie rzeczywistym |
| Ma prawdziwe OTEL SDK (Python itd.) | SDK + eksporter OTLP | Ślady + metryki + logi |
| To Twój własny worker .NET | AddObservability(...) | Wszystko plus rozproszone ślady |
Pełny kod
Wszystko dla zadań z tego artykułu. Wspólny bootstrap AddObservability, pełna konfiguracja Collectora (już z receiverem filelog/legacy pokazanym wyżej), docker-compose.yml i instalacja SigNoz są w załączniku Części 1 — użyj ich bez zmian.
Uruchom
# 1. Start SigNoz (one-time, self-hosted) -- full install in Part 1
git clone -b main https://github.com/SigNoz/signoz.git
cd signoz/deploy/docker && docker compose up -d # UI at http://localhost:8080
cd -
# 2. Start the stack (docker-compose.yml + collector from Part 1).
# The legacy .txt job runs by default and starts filling /var/log/legacy/*.txt
docker compose up -d --build
docker compose --profile jobs up -d --build # add the Python job
# 3. Run the PowerShell job on your host (PowerShell 7+), pointed at the collector's HTTP port:
$env:OTEL_EXPORTER_OTLP_ENDPOINT='http://localhost:5318'
pwsh ./backup-job.ps1
Usługi docker-compose dla zadań
Dodaj te dwie usługi do docker-compose.yml z Części 1 (legacy job działa domyślnie; job Python jest za profilem jobs):
# A job with NO OpenTelemetry awareness -- only writes .txt files. The collector's filelog
# receiver (in Part 1's collector config) reads them. Shares the job-logs volume with the collector.
legacy-job:
image: alpine:3.20
command: ['sh', '/opt/job/run-batch.sh']
environment: { LOG_DIR: /var/log/legacy, INTERVAL_SECONDS: '20' }
volumes:
- ./external-jobs/legacy-batch/run-batch.sh:/opt/job/run-batch.sh:ro
- job-logs:/var/log/legacy
networks: [blazorsignoz]
python-job:
build: { context: ./external-jobs/python }
profiles: ['jobs']
environment:
OTEL_SERVICE_NAME: python-etl-job
OTEL_EXPORTER_OTLP_ENDPOINT: http://otel-collector:4317
JOB_INTERVAL_SECONDS: '30'
depends_on: [otel-collector]
networks: [blazorsignoz]
external-jobs/legacy-batch/run-batch.sh
Zastępcze zadanie legacy. Bez SDK — tylko linie .txt, w tym okazjonalne wieloliniowe stack trace.
#!/usr/bin/env sh
# A stand-in for a legacy batch job that has NO telemetry SDK and cannot be changed:
# it only appends human-readable lines to a .txt log file.
#
# Run locally: LOG_DIR=./out INTERVAL_SECONDS=5 ./run-batch.sh
set -eu
LOG_DIR="${LOG_DIR:-./out}"
INTERVAL="${INTERVAL_SECONDS:-20}"
mkdir -p "$LOG_DIR"
logfile() { echo "$LOG_DIR/export-$(date '+%Y%m%d').txt"; }
emit() {
level="$1"; shift
printf '%s [%s] %s\n' "$(date '+%Y-%m-%d %H:%M:%S')" "$level" "$*" >> "$(logfile)"
}
emit INFO "legacy batch job started (pid $$)"
count=0
while true; do
count=$((count + 1))
records=$(( (count * 37) % 500 + 50 ))
emit INFO "run #$count: exporting nightly inventory snapshot"
emit INFO "run #$count: wrote $records records to dataset"
if [ $((count % 4)) -eq 0 ]; then
emit WARN "run #$count: 3 records skipped (failed validation)"
fi
# A multi-line error. The continuation lines do not start with a timestamp, so the
# collector's multiline rule attaches them to the [ERROR] entry as one record.
if [ $((count % 7)) -eq 0 ]; then
file="$(logfile)"
{
printf '%s [ERROR] run #%s: export failed: connection reset by peer\n' "$(date '+%Y-%m-%d %H:%M:%S')" "$count"
printf ' at LegacyExporter.Flush(batchId=%s)\n' "$count"
printf ' at LegacyExporter.Run()\n'
printf ' at main()\n'
} >> "$file"
fi
sleep "$INTERVAL"
done
external-jobs/python/requirements.txt
opentelemetry-api>=1.29,<2
opentelemetry-sdk>=1.29,<2
opentelemetry-exporter-otlp-proto-grpc>=1.29,<2
external-jobs/python/etl_job.py
"""
A standalone Python ETL job instrumented with the OpenTelemetry SDK. It exports traces, metrics,
and logs over OTLP to the collector (which forwards to SigNoz).
Env vars:
OTEL_SERVICE_NAME default "python-etl-job"
OTEL_EXPORTER_OTLP_ENDPOINT default "http://localhost:5317" (the demo collector's host port)
JOB_INTERVAL_SECONDS 0 = run once and exit; >0 = loop forever
"""
import logging
import os
import random
import time
from opentelemetry import metrics, trace
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.trace import Status, StatusCode
SERVICE_NAME = os.getenv("OTEL_SERVICE_NAME", "python-etl-job")
ENDPOINT = os.getenv("OTEL_EXPORTER_OTLP_ENDPOINT", "http://localhost:5317")
INTERVAL = int(os.getenv("JOB_INTERVAL_SECONDS", "0"))
resource = Resource.create(
{
"service.name": SERVICE_NAME,
"service.namespace": "blazor-signoz",
"service.instance.id": os.getenv("HOSTNAME", "local"),
}
)
tracer_provider = TracerProvider(resource=resource)
tracer_provider.add_span_processor(BatchSpanProcessor(OTLPSpanExporter(endpoint=ENDPOINT, insecure=True)))
trace.set_tracer_provider(tracer_provider)
tracer = trace.get_tracer("etl_job")
metric_reader = PeriodicExportingMetricReader(
OTLPMetricExporter(endpoint=ENDPOINT, insecure=True),
export_interval_millis=5000,
)
meter_provider = MeterProvider(resource=resource, metric_readers=[metric_reader])
metrics.set_meter_provider(meter_provider)
meter = metrics.get_meter("etl_job")
rows_counter = meter.create_counter("python.etl.rows_processed", unit="{row}", description="Rows processed by the ETL job")
runs_counter = meter.create_counter("python.etl.runs", unit="{run}", description="ETL job executions, tagged by outcome")
logger_provider = LoggerProvider(resource=resource)
set_logger_provider(logger_provider)
logger_provider.add_log_record_processor(BatchLogRecordProcessor(OTLPLogExporter(endpoint=ENDPOINT, insecure=True)))
logging.basicConfig(
level=logging.INFO,
handlers=[LoggingHandler(level=logging.NOTSET, logger_provider=logger_provider), logging.StreamHandler()],
)
log = logging.getLogger("etl_job")
def run_once(run_id: int) -> None:
with tracer.start_as_current_span("python.etl.run") as span:
span.set_attribute("etl.run", run_id)
log.info("ETL run %s starting", run_id)
with tracer.start_as_current_span("extract"):
time.sleep(random.uniform(0.05, 0.25))
rows = random.randint(100, 1000)
with tracer.start_as_current_span("transform"):
time.sleep(random.uniform(0.05, 0.25))
with tracer.start_as_current_span("load") as load_span:
time.sleep(random.uniform(0.05, 0.25))
if random.random() < 0.15:
load_span.set_status(Status(StatusCode.ERROR, "load failed"))
log.error("ETL run %s: load step failed", run_id)
runs_counter.add(1, {"success": "false"})
return
rows_counter.add(rows)
runs_counter.add(1, {"success": "true"})
span.set_attribute("etl.rows", rows)
log.info("ETL run %s finished: %s rows processed", run_id, rows)
def main() -> None:
run_id = 0
try:
if INTERVAL > 0:
log.info("Looping every %ss; exporting to %s", INTERVAL, ENDPOINT)
while True:
run_id += 1
run_once(run_id)
time.sleep(INTERVAL)
else:
run_once(1)
except KeyboardInterrupt:
pass
finally:
# Critical for short-lived jobs: flush batched telemetry before the process exits.
tracer_provider.shutdown()
meter_provider.shutdown()
logger_provider.shutdown()
if __name__ == "__main__":
main()
external-jobs/python/Dockerfile
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY etl_job.py .
ENV JOB_INTERVAL_SECONDS=30
ENTRYPOINT ["python", "etl_job.py"]
external-jobs/powershell/OtelExport.ps1
Dot-source tego pliku; udostępnia obie ścieżki telemetrii PowerShell.
<#
OtelExport.ps1 -- minimal OpenTelemetry helpers for PowerShell (7+).
Send-OtelLog / Send-OtelTrace : POST OTLP/HTTP+JSON straight to a collector (port 4318).
Write-JobLog : append JSON-lines to a file for the collector's filelog receiver.
OTLP/JSON gotchas handled: timeUnixNano as quoted strings, hex trace/span ids, integer enums.
#>
function Get-OtelNano {
$ms = [DateTimeOffset]::UtcNow.ToUnixTimeMilliseconds()
return ([long]$ms * 1000000).ToString()
}
function New-OtelId {
param([int]$Bytes)
$buffer = New-Object byte[] $Bytes
[System.Security.Cryptography.RandomNumberGenerator]::Fill($buffer)
return (($buffer | ForEach-Object { $_.ToString('x2') }) -join '')
}
function ConvertTo-OtelAttributes {
param([hashtable]$Attributes)
$list = @()
foreach ($key in $Attributes.Keys) {
$list += @{ key = $key; value = @{ stringValue = [string]$Attributes[$key] } }
}
return , $list # leading comma forces an array even for 0/1 elements
}
function Send-OtelLog {
param(
[Parameter(Mandatory)][string]$Message,
[ValidateSet('TRACE', 'DEBUG', 'INFO', 'WARN', 'ERROR', 'FATAL')][string]$Severity = 'INFO',
[string]$Service = 'powershell-job',
[hashtable]$Attributes = @{},
[string]$Endpoint = $env:OTEL_EXPORTER_OTLP_ENDPOINT
)
if (-not $Endpoint) { $Endpoint = 'http://localhost:5318' }
$severityNumber = @{ TRACE = 1; DEBUG = 5; INFO = 9; WARN = 13; ERROR = 17; FATAL = 21 }[$Severity]
$payload = @{
resourceLogs = @(@{
resource = @{ attributes = @(
@{ key = 'service.name'; value = @{ stringValue = $Service } },
@{ key = 'service.namespace'; value = @{ stringValue = 'blazor-signoz' } }
) }
scopeLogs = @(@{
scope = @{ name = 'powershell' }
logRecords = @(@{
timeUnixNano = (Get-OtelNano)
severityNumber = $severityNumber
severityText = $Severity
body = @{ stringValue = $Message }
attributes = (ConvertTo-OtelAttributes $Attributes)
})
})
})
}
$json = $payload | ConvertTo-Json -Depth 12 -Compress
try {
Invoke-RestMethod -Uri "$Endpoint/v1/logs" -Method Post -ContentType 'application/json' -Body $json | Out-Null
}
catch {
Write-Warning "OTLP log export failed: $($_.Exception.Message)"
}
}
function Send-OtelTrace {
param(
[Parameter(Mandatory)][string]$Name,
[int]$DurationMs = 100,
[ValidateSet('UNSET', 'OK', 'ERROR')][string]$Status = 'OK',
[string]$Service = 'powershell-job',
[hashtable]$Attributes = @{},
[string]$Endpoint = $env:OTEL_EXPORTER_OTLP_ENDPOINT
)
if (-not $Endpoint) { $Endpoint = 'http://localhost:5318' }
$endNano = [long]([DateTimeOffset]::UtcNow.ToUnixTimeMilliseconds()) * 1000000
$startNano = $endNano - ([long]$DurationMs * 1000000)
$statusCode = @{ UNSET = 0; OK = 1; ERROR = 2 }[$Status]
$payload = @{
resourceSpans = @(@{
resource = @{ attributes = @(
@{ key = 'service.name'; value = @{ stringValue = $Service } },
@{ key = 'service.namespace'; value = @{ stringValue = 'blazor-signoz' } }
) }
scopeSpans = @(@{
scope = @{ name = 'powershell' }
spans = @(@{
traceId = (New-OtelId 16)
spanId = (New-OtelId 8)
name = $Name
kind = 1 # INTERNAL
startTimeUnixNano = $startNano.ToString()
endTimeUnixNano = $endNano.ToString()
attributes = (ConvertTo-OtelAttributes $Attributes)
status = @{ code = $statusCode }
})
})
})
}
$json = $payload | ConvertTo-Json -Depth 12 -Compress
try {
Invoke-RestMethod -Uri "$Endpoint/v1/traces" -Method Post -ContentType 'application/json' -Body $json | Out-Null
}
catch {
Write-Warning "OTLP trace export failed: $($_.Exception.Message)"
}
}
function Write-JobLog {
param(
[Parameter(Mandatory)][string]$Message,
[string]$Level = 'INFO',
[string]$Path = './out/powershell-job.log',
[hashtable]$Attributes = @{}
)
$dir = Split-Path -Parent $Path
if ($dir -and -not (Test-Path $dir)) { New-Item -ItemType Directory -Path $dir -Force | Out-Null }
$entry = [ordered]@{ time = (Get-Date).ToString('o'); level = $Level; msg = $Message }
foreach ($key in $Attributes.Keys) { $entry[$key] = $Attributes[$key] }
($entry | ConvertTo-Json -Compress) | Add-Content -Path $Path
}
external-jobs/powershell/backup-job.ps1
Przykładowe zadanie używające obu ścieżek — pas i szelki.
. "$PSScriptRoot/OtelExport.ps1"
$ErrorActionPreference = 'Stop'
$service = 'powershell-backup-job'
$logFile = Join-Path $PSScriptRoot 'out/powershell-job.log'
$start = Get-Date
Send-OtelLog -Service $service -Severity INFO -Message 'Backup job started' -Attributes @{ host = $env:COMPUTERNAME }
Write-JobLog -Path $logFile -Level INFO -Message 'Backup job started (file path)'
try {
Start-Sleep -Milliseconds 400
$files = Get-Random -Minimum 50 -Maximum 500
Send-OtelLog -Service $service -Severity INFO -Message "Backed up $files files" -Attributes @{ files = $files }
Write-JobLog -Path $logFile -Level INFO -Message "Backed up $files files" -Attributes @{ files = $files }
$duration = [int]((Get-Date) - $start).TotalMilliseconds
Send-OtelTrace -Service $service -Name 'backup' -DurationMs $duration -Status OK -Attributes @{ files = $files }
Write-Host "Backup complete: $files files in ${duration}ms"
}
catch {
$message = $_.Exception.Message
Send-OtelLog -Service $service -Severity ERROR -Message "Backup failed: $message"
Write-JobLog -Path $logFile -Level ERROR -Message "Backup failed: $message"
$duration = [int]((Get-Date) - $start).TotalMilliseconds
Send-OtelTrace -Service $service -Name 'backup' -DurationMs $duration -Status ERROR
throw
}
Worker .NET w rozwiązaniu (łatwy przypadek)
Dla kompletności — worker z pełną telemetrią ze wspólnego bootstrapu. To zwykła aplikacja Microsoft.NET.Sdk.Worker z <ProjectReference> do Shared.Telemetry.
src/Worker.Jobs/Program.cs
using Shared.Telemetry;
using Worker.Jobs.Jobs;
using Worker.Jobs.Telemetry;
var builder = Host.CreateApplicationBuilder(args);
builder.Services.AddSingleton<WorkerTelemetry>();
var backendBaseUrl = builder.Configuration["Backend:BaseUrl"] ?? "http://localhost:5081";
builder.Services.AddHttpClient("backend", client => client.BaseAddress = new Uri(backendBaseUrl));
builder.Services.AddHostedService<InventoryReconciliationJob>();
// Same shared bootstrap as the web apps. A worker is not a web server, so ASP.NET Core
// instrumentation is off; HttpClient + runtime instrumentation stay on.
builder.AddObservability("worker-jobs", options =>
{
options.InstrumentAspNetCore = false;
options.ActivitySources.Add(WorkerTelemetry.ActivitySourceName);
options.Meters.Add(WorkerTelemetry.MeterName);
});
var host = builder.Build();
host.Run();
src/Worker.Jobs/Telemetry/WorkerTelemetry.cs
using System.Diagnostics;
using System.Diagnostics.Metrics;
namespace Worker.Jobs.Telemetry;
public sealed class WorkerTelemetry : IDisposable
{
public const string ActivitySourceName = "Worker.Jobs";
public const string MeterName = "Worker.Jobs";
public static readonly ActivitySource ActivitySource = new(ActivitySourceName);
private readonly Meter _meter = new(MeterName, "1.0.0");
private readonly Counter<long> _jobRuns;
private readonly Histogram<double> _jobDuration;
private readonly Counter<long> _itemsProcessed;
public WorkerTelemetry()
{
_jobRuns = _meter.CreateCounter<long>("worker.job.runs", unit: "{run}",
description: "Number of background job executions, tagged by job name and outcome.");
_jobDuration = _meter.CreateHistogram<double>("worker.job.duration", unit: "ms",
description: "Duration of background job executions.");
_itemsProcessed = _meter.CreateCounter<long>("worker.job.items_processed", unit: "{item}",
description: "Items processed by background jobs.");
}
public Activity? StartActivity(string name) => ActivitySource.StartActivity(name, ActivityKind.Internal);
public void RecordRun(string jobName, bool success, TimeSpan duration, int itemsProcessed)
{
var tags = new TagList { { "job.name", jobName }, { "success", success } };
_jobRuns.Add(1, tags);
_jobDuration.Record(duration.TotalMilliseconds, tags);
if (itemsProcessed > 0) _itemsProcessed.Add(itemsProcessed, new TagList { { "job.name", jobName } });
}
public void Dispose() => _meter.Dispose();
}
src/Worker.Jobs/Jobs/InventoryReconciliationJob.cs
using System.Diagnostics;
using System.Net.Http;
using System.Net.Http.Json;
using Worker.Jobs.Telemetry;
namespace Worker.Jobs.Jobs;
/// <summary>A periodic job. Each run starts a root span, calls the backend over an instrumented
/// HttpClient (→ worker-jobs → backend-api → db in SigNoz), logs, and records run metrics.</summary>
public sealed class InventoryReconciliationJob(
IHttpClientFactory httpClientFactory,
WorkerTelemetry telemetry,
IConfiguration configuration,
ILogger<InventoryReconciliationJob> logger) : BackgroundService
{
private const string JobName = "inventory-reconciliation";
private readonly TimeSpan _interval =
TimeSpan.FromSeconds(Math.Clamp(configuration.GetValue("Worker:IntervalSeconds", 15), 1, 3600));
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
logger.LogInformation("{JobName} starting; interval {IntervalSeconds}s", JobName, _interval.TotalSeconds);
try { await Task.Delay(TimeSpan.FromSeconds(5), stoppingToken); } // let the backend come up
catch (OperationCanceledException) { return; }
// Run once immediately, then start the timer so its clock begins AFTER the warm-up run.
await RunOnceAsync(stoppingToken);
using var timer = new PeriodicTimer(_interval);
while (await WaitForNextTickAsync(timer, stoppingToken))
{
await RunOnceAsync(stoppingToken);
}
}
private async Task RunOnceAsync(CancellationToken ct)
{
using var activity = telemetry.StartActivity($"job.{JobName}");
activity?.SetTag("job.name", JobName);
var stopwatch = Stopwatch.StartNew();
try
{
var client = httpClientFactory.CreateClient("backend");
var stats = await client.GetFromJsonAsync<ProductStats>("/api/products/stats", ct);
var count = stats?.TotalCount ?? 0;
activity?.SetTag("job.items", count);
logger.LogInformation("Reconciled {ProductCount} products (inventory value {InventoryValue})",
count, stats?.InventoryValue);
telemetry.RecordRun(JobName, success: true, stopwatch.Elapsed, itemsProcessed: count);
}
catch (OperationCanceledException) when (ct.IsCancellationRequested)
{
return; // graceful shutdown -- not a failure
}
catch (Exception ex)
{
activity?.SetStatus(ActivityStatusCode.Error, ex.Message);
logger.LogError(ex, "{JobName} run failed", JobName);
telemetry.RecordRun(JobName, success: false, stopwatch.Elapsed, itemsProcessed: 0);
}
}
private static async Task<bool> WaitForNextTickAsync(PeriodicTimer timer, CancellationToken ct)
{
try { return await timer.WaitForNextTickAsync(ct); }
catch (OperationCanceledException) { return false; }
}
private sealed record ProductStats(int TotalCount, int TotalQuantity, decimal InventoryValue, decimal AveragePrice);
}
Podsumowanie
Lekcja jest taka sama w każdym przypadku: Collector to szew. Aplikacje, którymi zarządzasz, eksportują OTLP; pozostałe są adaptowane w Collectorze — receiver filelog dla tekstu, processor resource nadający plikom tożsamość, json_parser dla ustrukturyzowanych linii, OTLP/HTTP dla wszystkiego, co może POSTować. Nadaj spójne service.name / service.namespace, a każde zadanie — C#, Python, PowerShell czy dziesięcioletni skrypt wsadowy — pojawi się obok siebie na dashboardzie, który hostujesz sam.
Reszta serii: Część 1 — observability Blazor Server (ze wspólnym kodem fundamentu) i Część 2 — pełnostackowa observability API C# z Postgres/SQL Server, albo wróć do indeksu serii.