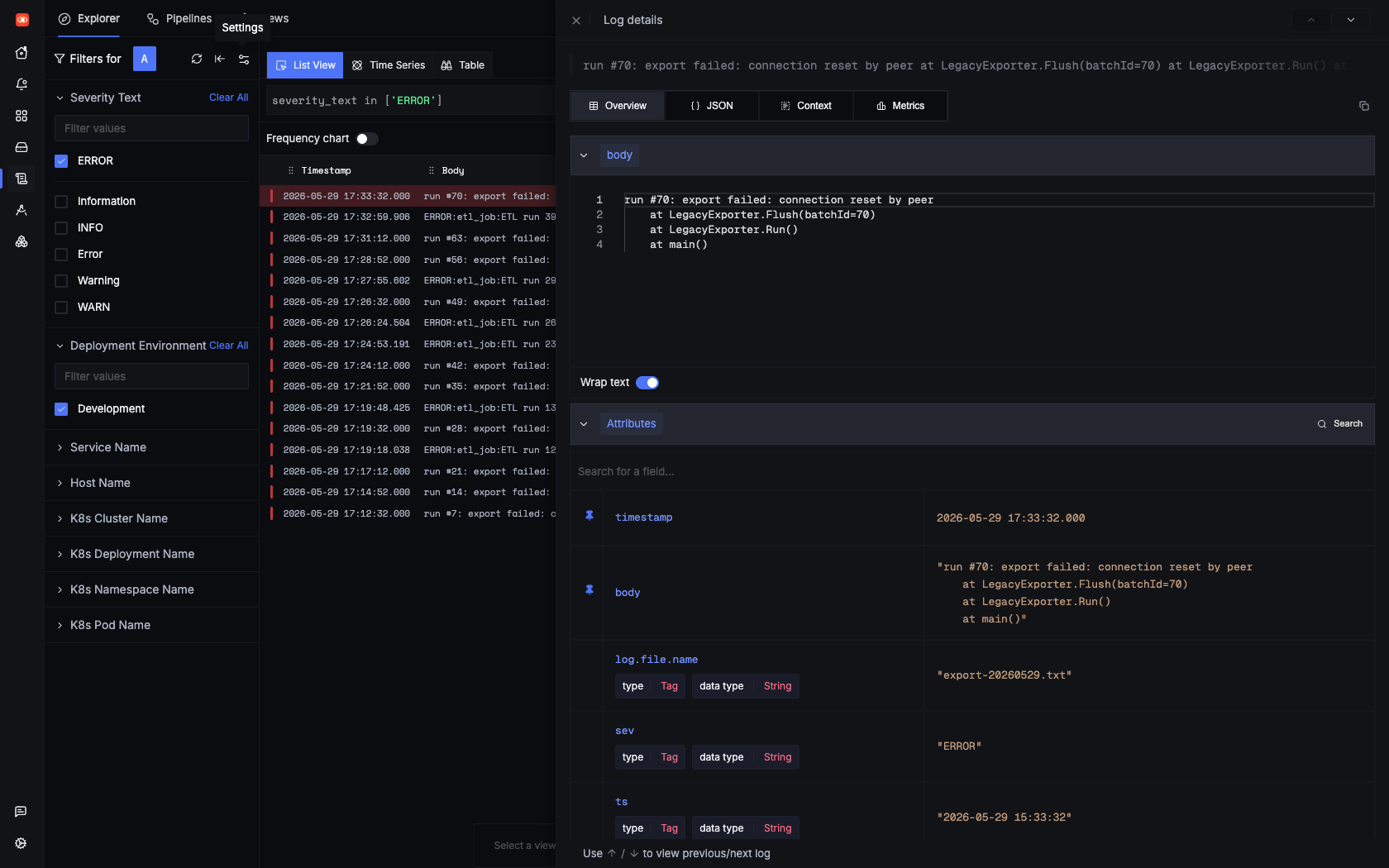
Jest wiele sposobów na tworzenie zależności między DAG-ami Airflow. Mój ulubiony, jak dotąd, to funkcja dataset. Nie ukrywam — bo jest tak prosta!
Przypomina tematy publish-subscribe ze świata inżynierii oprogramowania. Czy pasuje do Ciebie, zależy w dużej mierze od wyborów architektonicznych przy pisaniu DAG-ów. Jeśli wolisz zależności „jak należy” albo potrzebujesz większej personalizacji — tu jest dokumentacja, która Cię poprowadzi.
Wymagania wstępne:
- Wdrożenie Airflow z zależnymi DAG-ami.
- Podstawowe skrypty w Pythonie (kto by pomyślał, co?).
Przegląd kroków
Mamy dwa (lub więcej) DAG-i — pierwszy nazwijmy publisherem (DAG, który po zakończeniu uruchamia inne) i resztę subscriberami (DAG-i uruchamiane przez publishera).
- [Publisher i Subscriber] Importuj Dataset z airflow.datasets.
- [Publisher] Importuj DummyOperator.
- [Publisher] Napisz prosty task, który publikuje Dataset.
- [Subscriber] Ustaw parametr schedule, aby czytał Dataset z powyższego kroku.
Co to jest dataset?
Airflow zaprojektował tę funkcję dokładnie tak, jak sugeruje nazwa: aktualizacja/harmonogramowanie (na podstawie) zestawu danych (dokumentacja Airflow). Możesz używać jej ściśle w ten sposób, ale ja wolę wykorzystywać ją do tworzenia własnych „pub-sub” tematów w wdrożeniu Airflow.
Najprościej myśleć o dataset jako o wiadomości lub fladze publikowanej przez temat (Twój DAG). Jest publikowana wewnętrznie w Airflow, więc nie trzeba nic dodatkowego konfigurować. Po publikacji wszyscy subskrybenci zostaną uruchomieni, a wiadomość / flaga zostanie skonsumowana.
A co z niezawodnością — wielokrotne odczyty, pominięci konsumenci… skoro to klaster DAG-ów, a nie streaming IoT w czasie rzeczywistym, szczerze mówiąc, nie przejmuję się tym zbytnio, żeby nie over-engineerować. Jeśli w Twoim wdrożeniu są krytyczne DAG-i, od których zależą ludzkie życia — nie czytaj dalej i sprawdź, czy „normalna” zależność między DAG-ami w Airflow (jak tutaj) lepiej Ci pasuje 😉.
Którego operatora użyć?
DummyOperator! Tyle. Nic wymyślnego, nic skomplikowanego, brak sztywnych wymagań co do parametrów 🙅 Task publikujący dataset możesz dodać gdzie chcesz w DAG-u — pamiętając, że po jego wykonaniu uruchomią się wszystkie zależności. Oto jak:
notify_<someone>_<some_job>_finished = DummyOperator(
task_id="notify_<someone>_<some_job>_finished",
outlets=[Dataset("<some_job>_finished")],
)
Jak subskrybować dataset?

Użyję kodu bezpośrednio ze strony dokumentacji Airflow, bo wiemy, że każdy deklaruje DAG-i inaczej. Oto przykład z jedną modyfikacją — i to wszystko, co trzeba zrobić, aby subskrybować dataset:
import datetime
############### additional import required here
from airflow.datasets import Dataset
############### end of additional import
from airflow import DAG
from airflow.operators.empty import EmptyOperator
with DAG(
dag_id="my_dag_name",
start_date=datetime.datetime(2021, 1, 1),
############### modifying here
schedule=[Dataset("<some_job>_finished")],
############### end of modification
):
EmptyOperator(task_id="task")
Jak widać, wystarczy zmienić schedule DAG-a (i oczywiście zaimportować obiekt Dataset z airflow).
Kontakt
Dzięki za lekturę. Podoba Ci się to, co czytasz, ale brakuje czasu lub kompetencji, żeby ogarnąć analytics engineering? Sprawdź moje dane kontaktowe.
„Pub-Sub” architecture for your Airflow DAGs with Datasets został pierwotnie opublikowany w Lortech Solutions Blog na Medium, gdzie rozmowa trwa dalej dzięki podświetleniom i odpowiedziom czytelników.