Kluczowa uwaga na start
- Aby w pełni skorzystać z parametryzacji, produkcja musi umożliwiać przekazywanie flag i zmiennych do wykonywanego polecenia dbt.
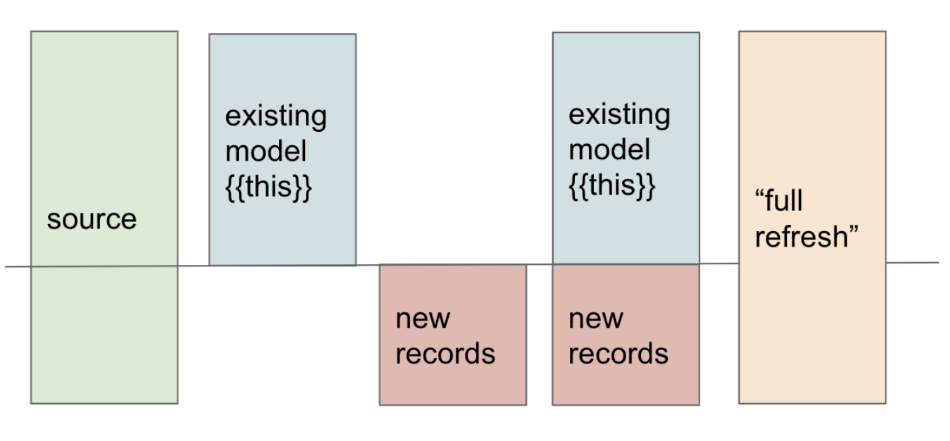
- Musisz uwzględnić funkcje okna, agregacje itd. w modelu, który chcesz uczynić przyrostowym. Z doświadczenia często wystarczy dłuższy okres przeładowania (np. ostatnie 30 dni), co nadal jest wydajniejsze niż codzienny full refresh. Uważaj — obliczenia łatwo zniekształcić, jeśli coś pominiesz.
- Znajdź wiarygodną kolumnę daty (lub timestamp, jeśli batchy częściej niż raz dziennie). „Wiarygodna” to taka, która odpowiada czasowi faktycznego zdarzenia.
Typowe błędy
- Zapomnienie o opóźnieniu dostarczania danych — jeśli producent może wysłać dane do 48 h po zdarzeniu — uwzględnij to, inaczej zdarzenia zginą, odfiltrowane przez logikę przyrostową. Bezpiecznie dodać jeden dzień przetwarzania.
- Niedokładna obsługa CI — jeśli CI za każdym razem robi full refresh tabel — dostosuj polecenia.
- Brak zabezpieczeń przed niepotrzebnym lub niechcianym full refresh — są legacy tabele, których nie wolno w pełni odświeżać (tak, to mi się zdarzyło), i inne przypadki, gdzie warunkowa logika oszczędza stres i koszty. Więcej w sekcjach poniżej.
Parametryzacja okna przeładowania przyrostowego
To proste. Jinja ma czytać z config modelu zamiast wewnątrz zapytania (szczególnie przy wielu blokach is_incremental()). Kroki:
- Dodaj parametr do config (nazwałem go lookback_window_in_days, ale wybór należy do Ciebie).
- name: <your_model>
description: "<your_description>"
config:
materialized: incremental
incremental_strategy: delete+insert
on_schema_change: append_new_columns
unique_key: surrogate_key
cluster_by: <date_column>
lookback_window_in_days: 2
- Na początku modelu ustaw zmienną czytającą ten parametr; dodaj wartość domyślną jako siatkę bezpieczeństwa.
{%- set lookback_window_in_days = config.get('lookback_window_in_days', default='2') -%}- Wybierz z this, odejmując sparametryzowane okno lookback.
---- your table logic here
and table_name.date_column >= (
select date_trunc(
day
, dateadd(day, -{{ lookback_window_in_days }}::int
, max(t.date_column))
) from {{ this }} t
)
Masz ustandaryzowane okno lookback. Możesz je dostosować do godzin lub timestampów — jak chcesz. Pomaga to w czytelności i dokumentacji, a przede wszystkim przy dwóch lub więcej blokach przyrostowych w jednym modelu. Zmiana okna — jedno miejsce i tylko tam.
Niestandardowe okno lookback
Co gdy w produkcji był błąd, a odkryłeś go dopiero po tygodniu? Możesz dodać możliwość przekazania liczby dni (lub innej wartości), która zostanie odczytana w bloku przyrostowym. Oto jak:
- Rozszerz blok is_incremental() o if-else, sprawdzający istnienie zmiennej (u mnie custom_lookback_window_in_days, nazwij po swojemu).
- Ustaw none jako domyślną wartość custom_lookback_window_in_days.
- Dodaj kolejny blok filtrujący czytający ze zmiennej niestandardowej.
Poniżej sparametryzowany kod z powyżej, rozszerzony o niestandardowe okno lookback:
-- here goes your table specification and key setting
-- here we start custom incremental processing
{% if is_incremental() %}
-- this part allows to do a partial backfill by specifying as a variable
-- number of backfill days required
-- accepts --vars '{\"custom_lookback_window_in_days\":\"<number>\"}'")
-- eg.: dbt run --select <your_model> --vars '{"custom_lookback_window_in_days":"10"}'
{% if var('custom_lookback_window_in_days', none) %}
and table_name.date_column >= (
select date_trunc(
day
, dateadd(day, -'{{ var("custom_lookback_window_in_days") }}'::int
, max(t.date_column))
) from {{ this }} t
)
{% else %}
and table_name.date_column >= (
select date_trunc(
day
, dateadd(day, -{{ lookback_window_in_days }}::int
, max(t.date_column))
) from {{ this }} t
)
{% endif %}
{% endif %}
I masz supermoc niestandardowych przeładowań! Bądź bardzo ostrożny przy ustawianiu zmiennych — pojedyncze lub podwójne cudzysłowy, ich brak — drobne, irytujące błędy, które spotykałem przez lata. Powyższa implementacja działa — gwarantuję :)
Tworzenie / wybór unique key
Potrzebujesz unique key, aby dbt wiedział, co zrobić przy wstawianiu nowych wierszy, gdy ten sam klucz już istnieje. Szczegóły strategii przyrostowych wykraczają poza ten artykuł — wybierz strategię, która Ci pasuje, ale polecam podejście do unique_key.
Jeśli masz solidny klucz główny — możesz go użyć. Zawsze polecam surrogate_key. Tabela jest czytelniejsza i zawsze wiesz, na jakiej ziarnistości masz unikalną kombinację wartości. Proces:
- Zainstaluj pakiet dbt_utils (jeśli jeszcze go nie masz).
- Dodaj makro generujące surrogate key:
{{ dbt_utils.generate_surrogate_key(['some_id' , 'another_id'
, 'some_name' , 'another_name'
, 'final_value']) }} as surrogate_keyPolecam dodać to na samym końcu modelu — przy finalnym SELECT. Widać wtedy, gdzie powstaje, i masz pewność, że nie zginie ani nie zmieni się w trakcie obliczeń.
Zostaje dodać to do config modelu.
Wskazówka: jako część surrogate key możesz użyć dowolnej kolumny. Makro obsługuje null-e, różne typy danych itd. Przeczytaj dokładnie tutaj.
Klastrowanie
Dla przyrostowych modeli o dużych wolumenach zwykle warto klastrować tabele. Jeśli używasz tych samych kolumn daty w logice przyrostowej w różnych warstwach pipeline’u, naturalne jest użycie tej daty jako klucza klastrowania. Klastrowanie wykracza poza ten artykuł — fragment definicji YAML modelu, żebyś wiedział, gdzie to trafia:
- name: <your_model>
description: "<your_description>"
config:
materialized: incremental
incremental_strategy: delete+insert
on_schema_change: append_new_columns
unique_key: surrogate_key
cluster_by: <date_column>
lookback_window_in_days: 2
Możliwości logiki warunkowej
Wymieniam trzy, które uznałem za najbardziej przydatne w przyrostowych pipeline’ach. Pełna lista funkcji Jinja dbt tutaj.
- execute
Przydatne, gdy chcesz uniknąć wykonania statementu podczas generowania manifestu — sprawdź parametr execute tak:
{% if execute %}
{{ some_macro('val1', 'val2') }}
{% endif %}- FULL_REFRESH
Głównie do dodatkowych makr lub zapytań DML.
Na przykład używasz sekwencji Snowflake w modelu, które trzeba dropować i tworzyć ponownie przy full refresh. Wykonaj makro, gdy flaga FULL_REFRESH jest włączona:
{% if execute and flags.FULL_REFRESH %}
{{ recreate_sequence('<sequence_name>', '<sequence_comment>') }}
{% endif %}- raise_compiler_error
Masz legacy tabelę i chcesz ograniczyć liczbę dni przeładowania (scenariusz z początku artykułu). Możesz rzucać wyjątki sprawdzające parametr lookback — czy mieści się w oczekiwanym zakresie?
{% if lookback_window_in_days < 0 or lookback_window_in_days > 100 %}
{{ exceptions.raise_compiler_error("This table max reload is 100 days") }}
{% endif %}Kontakt
Dziękuję za przeczytanie. Podoba Ci się przekazywana wiedza, ale brakuje czasu lub kompetencji, aby uporządkować analytics engineering? Sprawdź moje dane kontaktowe.
Przenieś logikę przyrostową dbt Core na wyższy poziom został pierwotnie opublikowany w Lortech Solutions Blog na Medium, gdzie rozmowa trwa dalej dzięki podświetleniom i odpowiedziom czytelników.